
|
|
 This page describes a technique for parsing web pages for small-scale web
data mining projects in Java or other languages. Many modern web sites
generate web pages using JavaScript, e.g., with jQuery, AJAX, and other
techniques. So parsing HTML does not always provide the content displayed
to a user visiting the site with a browser. Furthermore, it is sometimes
useful to determine the location of page objects after they have been
rendered.
This page describes a technique for parsing web pages for small-scale web
data mining projects in Java or other languages. Many modern web sites
generate web pages using JavaScript, e.g., with jQuery, AJAX, and other
techniques. So parsing HTML does not always provide the content displayed
to a user visiting the site with a browser. Furthermore, it is sometimes
useful to determine the location of page objects after they have been
rendered.
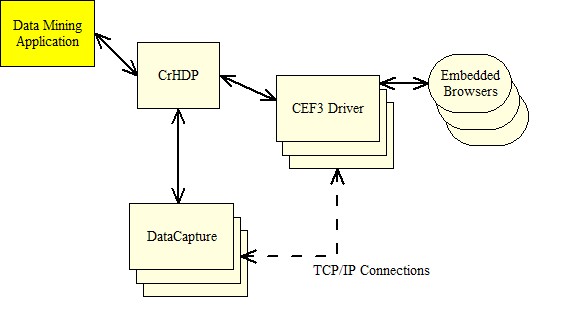
A proper parser must download the HTML for the page, parse it, apply JavaScript, apply cascading style sheets, and render the page. In other words, part of a web data mining system is essentially a browser. Building and maintaining a web browser component as part of a web data mining project is monumental. Embedding an existing browser is a more efficient approach.
The first part of this article describes the history of a decade long search for a stable parsing method that can be used by Java. The final section describes my current effort, CrHDP, which embeds Chromium to parse web pages.
My quest started in the early 2000's when the local newspaper reorganized the comics page, removing some of my favorite strips. I started reading the missing strips online and decided to create a single page for them. A colleague had developed a tag processor as a servlet, so I used his tag that would extract the nth image from a page and embed it in a new page. This technique worked well for awhile and only needed adjustments occasionally.
Two changes occurred that required me to change my approach. First, the pages from which I was scrapping comics started changing more frequently. I decided to develop a machine learning system to help identify the daily comic on each comic web page. Second, one site started using JavaScript to dynamically modify the page to include the image URL of the comic. In order to extract the URL, my software needed to download the page, parse it, and apply JavaScript code to update the image address.
The machine learning system is described in on The Comics Miner page and will not be discussed further.
My first attempt at parsing web pages in Java used the HTML Parser. This software worked well but did not process JavaScript. So I moved to embedding the Mozilla Gecko browser using JRex. It is my recollection that JRex used Java JNI (native C code) to link JRex into the Gecko XPCOM libraries; however, I'm not sure anymore. At the time I started using JRex in the mid 2000's, it was already an abandoned project. Because JRex ran in the Java virtual machine that contained my machine learning code, a crash in the JNI code would crash the whole system.
My next attempt at web page parsing used the Cobra Toolkit that was part of the Java Lobobrowser project. The system worked well but was abandoned. Eventually, the JavaScript engine became dated and would not execute properly in some of the pages I needed to parse. The nice thing about Cobra is that I could find the location of images on the rendered pages. Image location is important in some algorithms that identify salient content, e.g., VIPS.
In 2010, I discovered Crowbar, a XULRunner application written in JavaScript for web scraping. Crowbar processes requests sent to it over a socket. It loads the requested page into a Gecko browser and returns the DOM after JavaScript has been applied.
In 2011, I tried to use two other packages: HtmlUnit and forklabs-javaxpcom. The former did not render pages, so I could not extract the page location of images. The forklabs code was built on JavaXPCOM. I started using the code at about the time Mozilla announced that JavaXPCOM would no longer be supported.
I finally used Crowbar as a model and produced a XULRunner application that would allow multiple concurrent, distributed Gecko parsers to run. The parsers were accessed via sockets and could run on any machine that supported XULRunner. A Java library was developed to manage the processes, send requests, capture output, and handle anomalous situations.
The parsers operated in three modes. In the first, the page would be rendered, and a list of images would be returned along with the image source URL, size, and page location. In the second mode, only the HREF attributes of anchor tags would be returned. In the final mode, the full DOM, modified to include the location of page objects, would be returned. I named this parser the Hip Dragon Parser (HDP) with the "dragon" referring to the Mozilla dragon icon.
The parsers could not be run headless on Windows XP, but under Linux, they could be run headless using a virtual frame buffer. Under Windows 7, the system runs headless when launched as a scheduled task, so I suspect there is a way to run the parsers in headless mode when launched in normal mode.
The system was stable with versions of XULRunner up to version 16. With version 17 and above, the parsers would intermittently crash or lock up. I made several attempts to debug the code, even building a version of XULRunner from scratch. But I eventually abandoned the hope of running newer versions of XULRunner. Embedding is mostly not supported by Mozilla, which makes obtaining help more difficult.
 My current parser is much like HDP; however, I embed Chromium instead of
Mozilla Gecko. I had originally avoided using any WebKit-based system
since access to the DOM was not directly supported. Even when DOM access
was added, complete information is not exposed, e.g., natural-width is
not exposed. But by using JavaScript injection, my parser can access
the DOM and obtain all the information I gathered using HDP.
My current parser is much like HDP; however, I embed Chromium instead of
Mozilla Gecko. I had originally avoided using any WebKit-based system
since access to the DOM was not directly supported. Even when DOM access
was added, complete information is not exposed, e.g., natural-width is
not exposed. But by using JavaScript injection, my parser can access
the DOM and obtain all the information I gathered using HDP.
I am using the The Chromium Embedded Framework (CEF3) to build the parser. CEF3 is a C library with a C++ wrapper layer. There are also bindings for other languages including Java and C#. The best approach would have been for me to write my wrapper in C++ to maintain the high level of portability that HDP has; however, I decided not to relearn a language I hadn't used in years. The Java bindings did not seem to have the power I needed, so I decided to build my code in C#. The issue of portability might be resolved as Microsoft has announced plans to port .NET to Linux and OS/X or by using Mono.
There are two C# bindings. I used Xilium.CefGlue. My C# code performs the same tasks as the XULRunner JavaScript code I wrote for HDP. It listens for parse requests on a socket, causes the embedded browser to navigate to the requested page, and extracts information from the DOM after JavaScript has been applied and the page has been rendered. Since web pages can hang waiting for some external resource, the code implements a timeout and will return the DOM created at the point the timeout occurred.
Multiple parsers can run concurrently on one or more machines. The production version of the code runs headless; however, I have an experimental version that runs inside a Windows form. This version is useful for viewing the causes of slow page loads.
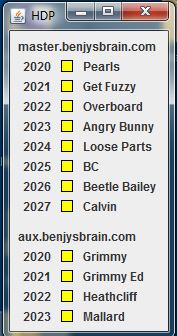
The image above this text shows the CrHDP monitor. CrHDP is running on two hosts. The first has eight parsers running, while the second has four parsers. The data mining application and the monitor GUI run on the first machine. Each row in the display gives the port number on which the parser is listening for requests, a status box, and a user-supplied tag identifying the site being parsed. A yellow box means the parser is busy while a white box means the parser is idle. Other colors represent error conditions.
I have tried to address two problems in dealing with real web pages. First, many web pages are created with elements from a number of servers. A delay in any server, e.g., an ad server, can cause the end-of-page event to be delayed from firing. Poorly written JavaScript can also prevent the page loaded event. In many cases the salient parts of the page have been loaded, so both HDP and CrHDP support timeouts. If the end-of-page event has not occurred before a user-defined timeout, the current state of the DOM is returned.
The second problem deals with the current state of advertising on modern web sites. As pages are loaded, dynamic changes can be made to the page to include advertisements. For example, the DOM can be rewritten to place an ad over the salient content or to shift the page content to the right to made room for an ad. Data mining that relies on page location of the content can fail if ads misplace useful content. CrHDP has a feature to block JavaScript from sites that are not on the primary host. This feature has improved the parsing speed of the parsers and reduced the number of data mining issues related to ad placement. There is an override feature so that some sites are not blocked.
The current version of the code is based on the CEF 3 2454 branch and was completed in November of 2015. The version fixed a bug where temporary files were not deleted.
I am building a JavaFX version of CrHDP with an alpha version completed 5/2016. Unfortunately, it is difficult in JavaFX to implement the feature of CrHDP that allows blocking of JavaScript from some ad sites.
I decided to build a version of CrHDP that would run under Linux. Because
of some support issues for CefGlue under Linux and questions about Linux
.Net support, I decided to implement Linux CrHDP in C++. The implementation
is based on the cefsimple sample program that comes with the distribution
of CEF3. As of 5/2017, I have a working version of Linux CrHDP that has
all the features of the Windows version.
